Contents
Try your best to follow instruction below but you do not need to strictly follow. Instead, you’re welcome to make suggestions/changes. If you have questions, do not hesitate to ask. Don’t be afraid that your code does not look right or pretty. We can discuss by openning an issue
If having any suggestions, open an issue too.
How to contribute code?
Examples: I forked amber-md/pytraj repo to my account hainm/pytraj
$ # download my branch to my computer
$ git clone https://github.com/hainm/pytraj/
$ cd pytraj
$ # create a new branch
$ git branch your_feature_name
$ git checkout your_feature_name
$ # make changes, do testing, ...
$ # use git add and git commit to record new change (google please)
$ # then push the code to your repo on github
$ git push origin your_feature_name
$ # then make a pull request to amber-md/pytraj
$ # (sounds complicated but not really, just try it and feel free to ask us for any questions)
Above is very minimal instruction to start up. Please google for further detail.
Use six to write your compat code. We put all common stuff in pytraj.compat
Note
currently, I (Hai) are only working on Python3 since it’s much better Python2 (google why).
conda recipe:
$ git clone https://github.com/Amber-MD/conda-recipes
$ cd conda-recipes
$ # build libcpptraj if needed
$ conda build libcpptraj/
$ # then build pytraj
$ ./pytraj/run_build.sh
$ # use run_build.sh (instead of conda build pytraj/) because we build 3 times for py27, py34, py35
Need: auditwheel (require python >= 3.4), twine
$ python -m pip wheel ./pytraj-1.0.3.tar.gz
$ auditwheel repair pytraj-1.0.3-cp27-cp27mu-linux_x86_64.whl
$ twine upload wheelhouse/pytraj-1.0.3-cp27-cp27mu-manylinux1_x86_64.whl
$ # want to upload slightly modified version: change "1.0.3" to "1.0.3.1" (or similiar)
Trick:
Use conda to create different python envs, then build corresponding wheel, then use auditwheel to repair all the wheels
You don’t need to activate new env, just specify python exe path:
$ ~/anaconda3/envs/py27_pypi/bin/python -m pip wheel ...
Check pytraj.all_actions for example.
def new_method(traj, ...):
# make sure to use frame iterator like below
for frame in traj:
do_something_cool_with_frame
return something_you_want
# that's it. Now you can plug your method to ``pytraj.pmap``
from pytraj import pmap
pmap(n_cores=4, func=new_method, traj=traj, ...)
if you don’t want to write code for pmap, just tag it with noparallel decorator
from pytraj.decorators import noparallel
@noparallel
def new_method(...):
...
New method, new change must have testing code.
Currently, all testing codes are in pytraj/tests/ folder.
$ cd tests
$ cp template_unittest.py test_your_new_method_name.py
$ # To run all tests
$ nosetests -vs .
$ # to speed up the test
$ nosetests --processes=n_cpus_you_wants -vs .
$ # to run specific file
$ python test_your_new_method_name.py
$ # clean
$ git clean -f
Try to put all external codes (six.py, ...) in pytraj/externals/ folder.
pytraj always welcomes code contribution. It’s recommended to put your name in the code you write. However, for the sake of clearness, just put something very short, like Copyright (c) 2010-2013 your_first_and_last_name and give full details of your contribution, license in pytraj/licenses/ folder.
Note
make sure to install pytraj, cpptraj, numpy, ipython, matplotlib, memory_profiler, psutil. Install sphinx-bootstrap-theme too
$ git clone https://github.com/Amber-MD/pytraj
$ cd pytraj
$ git checkout gh-pages
$ cd doc
$ make html
There are some tricks:
let ipython run your code in .rst file by adding ipython directive:
.. ipython:: python
let ipython run your notebook and automatically convert to html file, add notebook directive:
.. notebook:: data/plot_rmsd_radgyr_correlation.ipynb
:skip_exceptions:
let’s see other tricks in:
source/tutorials/*rst
Note
to update layout for website, should modify ‘source/_static/my-styles.css’ file.
I (Hai) prefer to use ipython notebook to write tutorial and include it in website. sphinx will run the notebook, convert to html file, insert it in correct page. But let’s start with different ways to make a tutorial. First, make sure to:
$ git checkout gh-pages
use ipython directive: you just write the code and sphinx will run it for you. check:
$ doc/source/tutorials/basic_examples.rst
This is how the page look likes basic_examples.
Click Source in that page for raw code.
use ipython notebook directive: you just write the code and sphinx will run it for you. This approach will have more richful layout. check:
$ doc/source/tutorials/plot_correlation_matrix.rst
This is how the page look likes plot_correlation_matrix.
Click Source in that page for raw code.
Two above approaches are performed on the fly when you make the doc. If you don’t want to rerun your notebook, you can run once, convert it to html file and include it in rst file:
$ ipython nbconvert --to html your_notebook_name.ipynb
$ # check doc/source/tutorials/lysozyme_order_parameter_.rst
$ # (basically you just need to use .. raw:: html directive)
This is how the page look likes lysozyme_order_parameter.
Click Source in that page for raw code.
Note
This ‘push’ is for those who have permision to log in to ambermd account on anaconda.org
website: anaconda.org/ambermd
install ruby (google how)
install travis:
$ gem install travis
install anaconda-client:
$ conda install anaconda-client
In your terminal, log in to anaconda account:
$ anaconda login
$ # just enter your username and password
generate anaconda token to give travis permision to push data in ambermd channel in anaconda.org:
$ git clone https://github.com/Amber-MD/pytraj
$ cd pytraj
$ # generate token
$ TOKEN=$(anaconda auth --create --name MyToken)
$ echo $TOKEN
need to use travis to encrypt our token:
$ travis encrypt TRAVIS_TO_ANACONDA=secretvalue
make code change, commit, push to github so travis can build pytraj and libcpptraj:
$ # after successful build, travis will push to anaconda.org by below command
$ anaconda -t $TRAVIS_TO_ANACONDA upload --force -u ambermd -p pytraj-dev $HOME/miniconda/conda-bld/linux-64/pytraj-dev-*
$ # check devtools/travis-ci/upload.sh and .travis.yml files for implementation.
It’s good to measure how well you code is tested. Basically, you should write all possible tests to make sure all (most) lines of codes executed:
$ nosetests -vs --processes 6 --process-timeout 200 --with-coverage --cover-package pytraj
Explanation for above line:
--processes 6: use 6 processes to speed up testing--with-coverage: use coverage module to measure your code coverage--cover-package pytraj: only care about code in pytraj
In the final output, you should get something like:
pytraj.io 170 29 83% 20-21, 29-30, 213-215, 217, 258, 357, 428, 439, 450-456, 493-503, 516
The numbers after 83% show the line numbers in pytraj.io module (io.py) that are not executed in test files. if I open the 516-th line in io.py file, I will see:
514 def load_single_frame(frame=None, top=None, index=0):
515 """load a single Frame"""
516 return iterload(frame, top)[index]
This means that this method has never been tested. So just write a test case for it to increase the coverage score.
Use gdb
$ gdb python
(gdb) run your_python_script.py
(gdb) bt
This is how the output looks like after you typed bt command:
#13 0x00002aaac32fc8a4 in __pyx_pw_7_lprmsd_1lprmsd (__pyx_self=0x0, __pyx_args=<value optimized out>, __pyx_kwds=<value optimized out>) at mdtraj/rmsd/_lprmsd.cpp:1739
We recommended to use cython to write or wrap high performance code. Please don’t use cimport numpy, use memoryview instead
Since pytraj will be bundled with AmberTools in Amber, it’s important that we should commit cythonized file too. The main idea is that user only need C++ compiler and cpptraj, nothing else.
For some unknow reasons, I (Hai) got segmentation fault if import numpy in the top of the module when working with *.pyx file. It’s better to import numpy locally (inside each method).
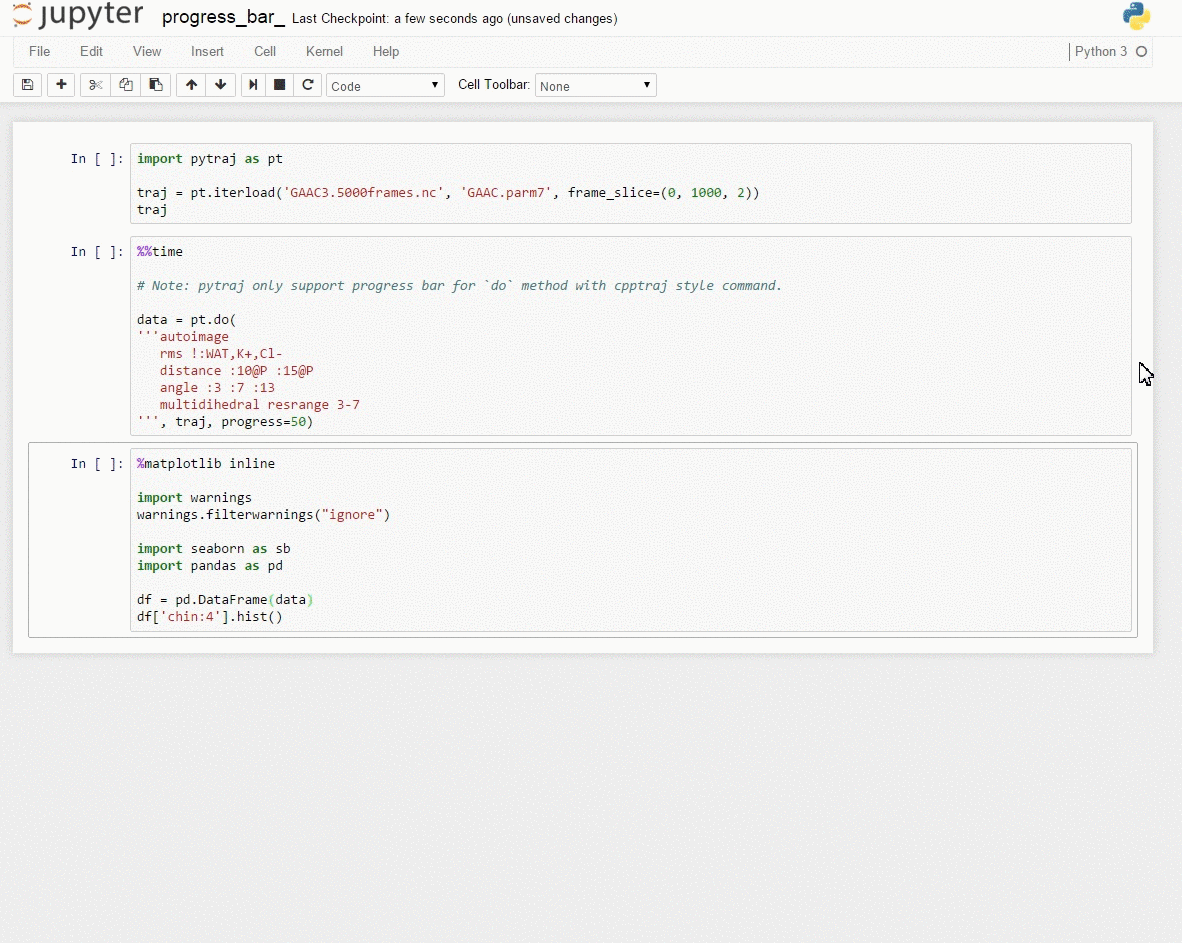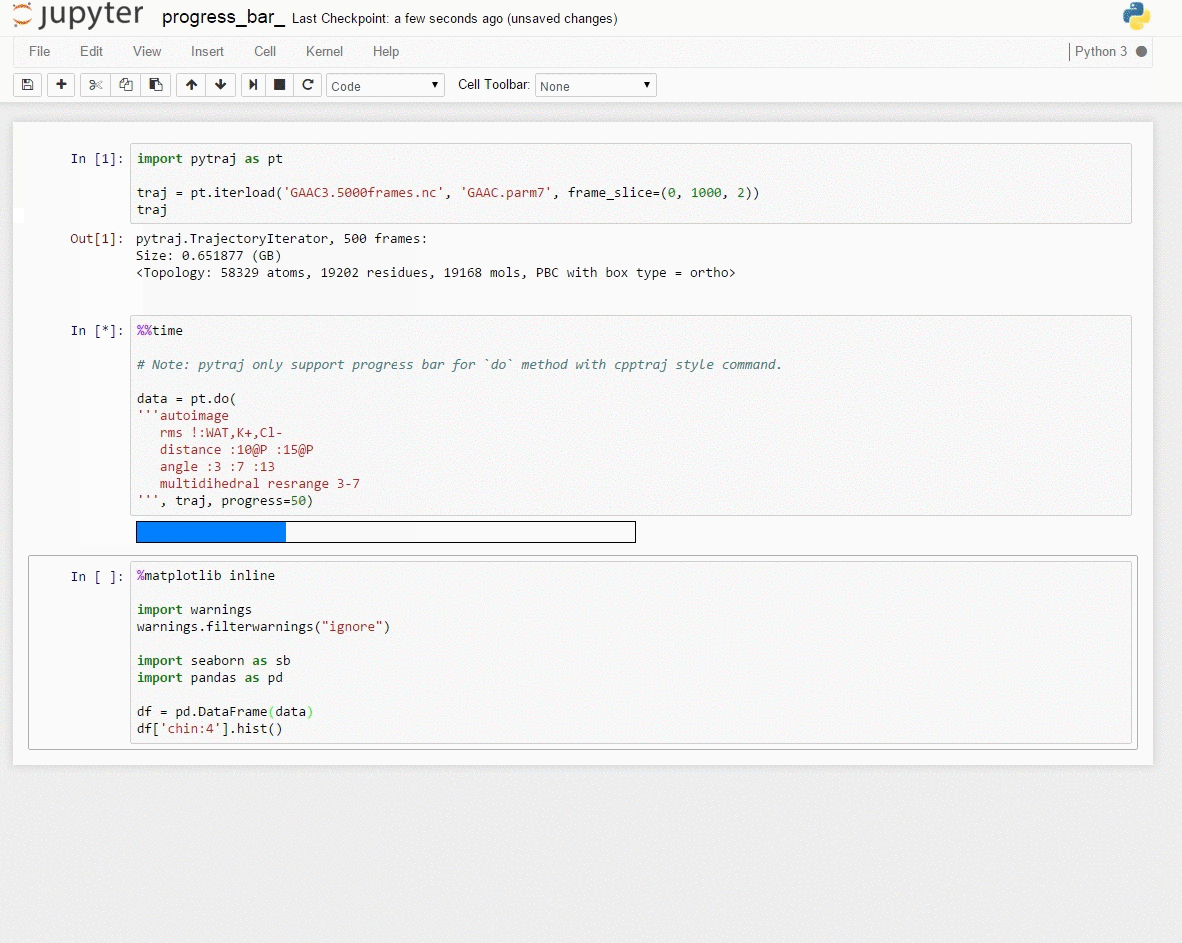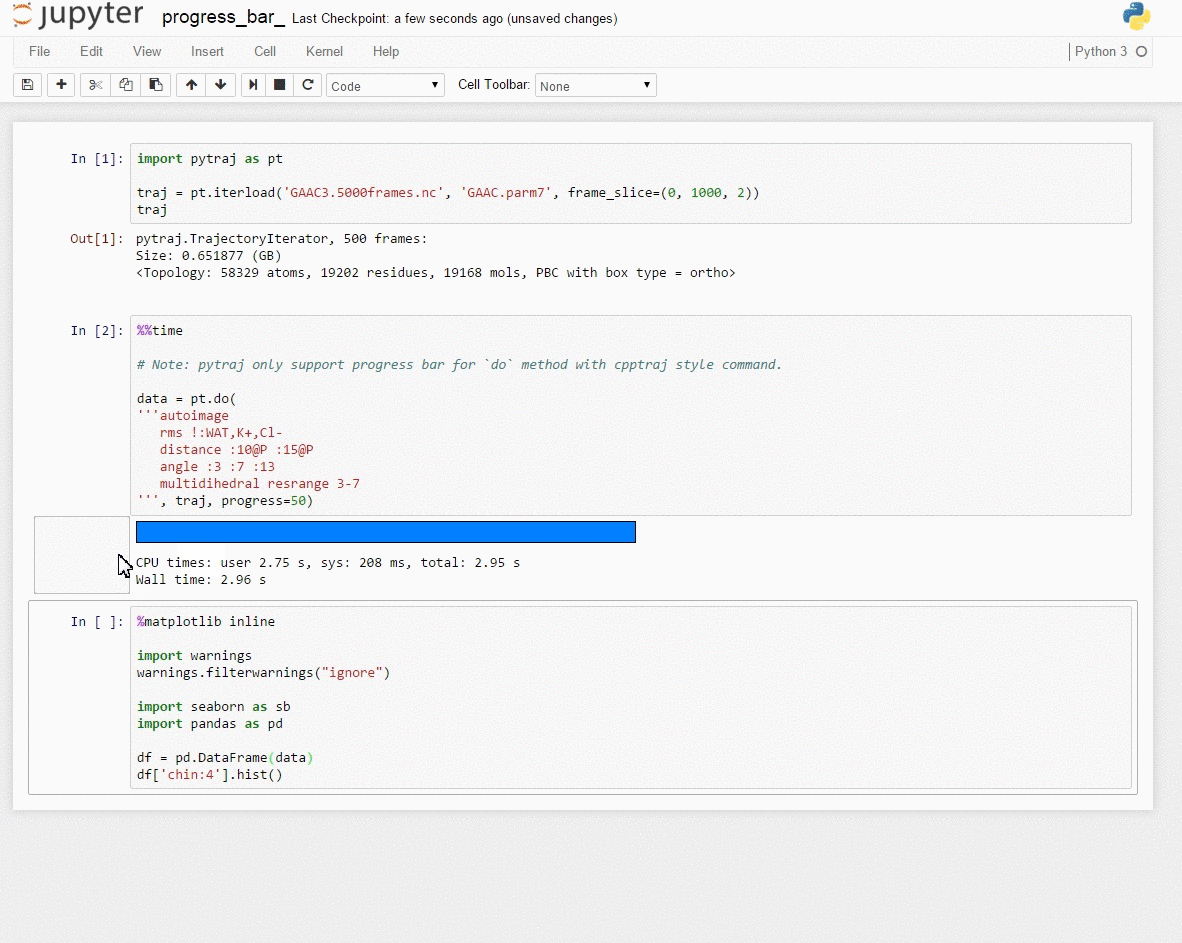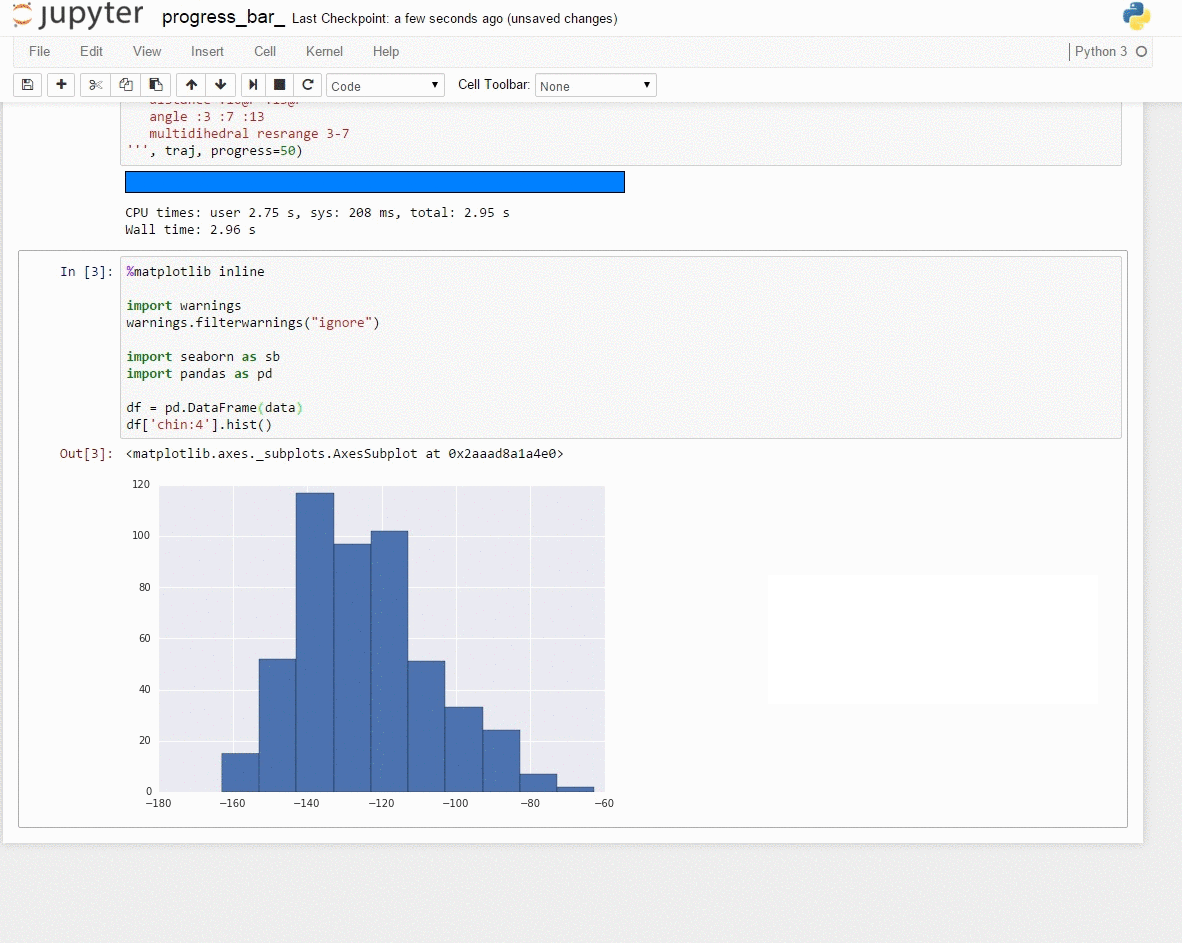
I (HN) tried different programs to record screen but only http://recordit.co/ works well (easily to export to high quality GIF without using addional program). See demo here
{kind=link}